Accelerated Quantum Supercomputing with NVIDIA DGX Quantum: Real-Time GPU-CPU-QPU Integration from the Diraq Lab
Why NVIDIA DGX Quantum and real-time feedback matter right now
In our recent Quantum Machines’ Seminar with Diraq, we witnessed results from the first system that tightly couples CPUs, GPUs and a QPU for hybrid quantum–classical workflows, NVIDIA DGX Quantum, bringing bounded-latency integration into real experiments. The goal is straightforward. Put heavy classical compute resources for AI, decoding, and model updates inside the timescale of a running quantum sequence so you can calibrate faster, correct earlier, and scale more smoothly. This marks a practical step from research progress toward accelerated quantum supercomputing.
Diraq is one of the first users of Quantum Machines and NVIDIA DGX Quantum and in this seminar, we hear all about its experience first-hand with this new architecture reference system for quantum-classical integration.
Check out the full QM-Diraq seminar On-Demand Seminar: Realtime classical-quantum computations when your qubits are fast

NVIDIA DGX Quantum pairs NVIDIA Grace Hopper with Quantum Machines’ OPX1000 via an ultra-fast OP-NIC over PCIe interconnect, offering perfect compliance with NVIDIA NVQLink, their open architecture blueprint for quantum-classical integration. QM’s OP-NIC acts as a real-time interconnect able to integrate the OPX1000 quantum system controller with any CPU/GPU server with bounded latency. Round-trip latency is under 4 microseconds (at least 1,000× faster than typical alternatives), which keeps optimization and feedback inside coherence windows and drift budgets. In practice, that brings advanced classical compute into live quantum sequences.
Diraq’s high-impact use cases for GPU-CPU-QPU integration
Diraq builds CMOS-compatible spin qubits and runs fast experiments where latency and compute headroom set the pace. There are several incredible experiments from Diraq where they expect the new architecture to have an impact. All of which are important milestones recognized by the entire community.

Figure 1 – Some of the use cases where Diraq sees promise for CPU-GPU integration.
1) Calibration feedback that outruns TLS switching
By interleaving simple circuits between shots, Diraq tracks two-level systems in real time and feeds updated calibration parameters back into the sequence fast enough to improve fidelities. The same workflow reveals spatio-temporal noise correlations that would otherwise degrade performance but are too difficult to compute on FPGA.
References: Appl. Phys. Lett. 124, 114003 (2024); Sci. Rep. 15, 11065 (2025); Nat. Commun. 16, 3606 (2025).
2) Algorithmic initialization that beats T1
Combining quantum non-demolition measurements with conditional operations, Diraq demonstrated heralded initialization beyond thermal equilibrium at 1 K and 85 mT, where thermal energy is about ten times the qubit energy. Machine learning then learns SPAM from the same stream but this needed to be done offline before DGX Quantum. Reference: Nature 627, 772–777 (2024).
3) Toward mid-circuit measurement and decoding within T2
A mid-circuit measurement sequence on spin qubits is in preparation with the goal of decoding syndromes within decoherence limits and mitigating backaction in real time. This is a natural fit for GPU-side estimation while OPX1000 runs deterministic pulse logic.
Reference: manuscript in preparation, stay tuned!
Week 1 on DGX Quantum: four hybrid experiments up and running
In the first week, the joint Diraq and QM teams worked side by side and brought four hybrid experiments online. See pictures directly from the lab in Figure 2!
- A round-trip latency loop between OPX1000 and Grace Hopper to characterize bounded latency. Shorter than 4 µs round-trip shown!
- Real-time correlated measurements, replicating a protocol from PRX Quantum 5, 010301 (2024).
- Closed-loop optimization of Rabi oscillations using the QM reinforcement learning recipe to simultaneously optimize the amplitude and frequency of an X-gate.
- Heralded initialization where the repeat decision is taken on the DGX side.

Figure 2 – Four of the results that the Diraq and QM teams obtained in the first week using NVIDIA DGX Quantum combined with Diraq’s QPU.
One week of work, four experiments that showcase the potential of using GPUs, computing and responding within quantum timescales. The Diraq teams now expects to integrate NVIDIA DGX Quantum even further into their experimental workflow to utilize its powerful resources whenever possible. They will work to extract even more out of the real-time feedback on experimental parameters, integrating auto-tuning, and substantiate a general-purpose noise learning tool to expand the capabilities of keeping devices in tune.
Hybrid quantum-classical computing: from classical chips to qubits (and back again)
On stage, QM’s Dean Poulos walked through a live case study: optimizing a three-qubit GHZ state using reinforcement learning. Dean also introduced a new DGX Quantum learning framework that abstracts low-level comms and creates QUA-native “learnable parameters” and observation streams. Planned integration with CUDA-Q will let teams build reusable libraries on this hybrid architecture. The software scaffolding is growing strong!
Read more about this GHZ state experiment in our recent blogpost.
This is the real selling point of tight integration. It is not enough that multiple resources communicate. The ability for information to flow forward and backwards within ultra-short latencies allows the usage of information, processed by different types of compute resources, during the quantum protocols. This allows for powerful and essential adaptive quantum circuits and calibrations.
NVIDIA DGX Quantum specs and capabilities — quick map
NVIDIA DGX Quantum combines a Grace Hopper system with the Quantum Machines OPX1000 controller over OPNIC over PCIe for bounded-latency hybrid quantum-classical computing. Diraq has confirmed once more the sub-4 µs GPU-controller round trip. On the control side, the OPX1000 pulse processing unit (PPU) delivers deterministic, pulse-level control with active reset ~100 to 200 ns, branching, vector math, and stream processing, while the software framework exposes QUA parameters and observation streams so GPU and CPU algorithms can act inside the experimental timescale, with planned CUDA-Q integration.
This is the tightest integration between a classical superchip with a quantum processing unit that the world has ever seen.
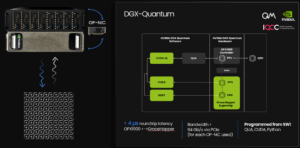
Figure 3 – Highlights of Quantum Machines’ and NVIDIA DGX Quantum, the reference architecture for CPU-GPU-QPU integration, showcasing less than 4 µs roundtrip latency, high bandwidth, and very flexible programming.
What this unlocks today: low-latency quantum computing with real-time quantum feedback and feed-forward with a general classical compute architecture, for faster, more reliable calibrations, mid-circuit measurement, frequency tracking, parametric control, and early quantum error correction (QEC) and fault-tolerant quantum computing (FTQC) research where decoders, estimators, and RL-based tuning run during the sequence, not after. This is what DGX Quantum was built for.
Try NVIDIA DGX Quantum
Quantum control is now a full-stack computing problem. With NVIDIA DGX Quantum in its alpha stage, classical AI, estimation, and decoding operate on the same clock as the pulses you coded for the OPX1000, turning offline insights into in-sequence actions.
If you are exploring QEC, fast calibration, adaptive experiments, or have other ideas of use cases to explore, write us to try NVIDIA DGX Quantum on real hardware and map your first hybrid loops.

