
QM’s Orchestration Platform for
HPC Centers and Hubs



QUANTUM FOR HPC
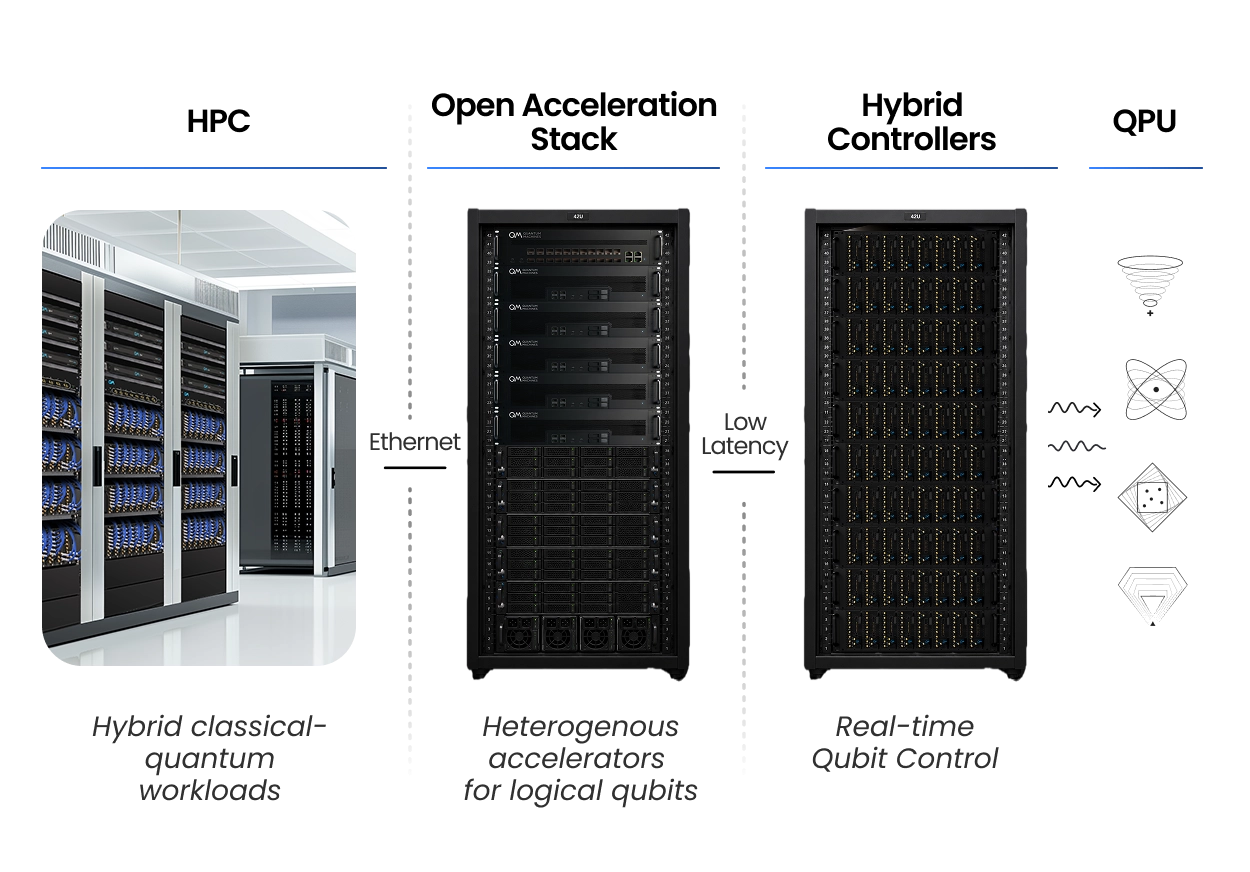
HPC centers are becoming a natural home for quantum computing, where quantum processors can operate as specialized accelerators inside heterogeneous classical infrastructures. To make this practical, quantum systems must connect to familiar HPC workflows while still meeting the real-time requirements of quantum control, calibration, feedback, and error correction. This requires more than submitting circuits from a server: it requires a layered classical-quantum architecture where schedulers, compute nodes, accelerators, controllers, and QPUs work together without placing real-time quantum operations on the HPC critical path.
Quantum Machines’ Orchestration Platform enables this architecture by connecting HPC environments to hybrid controllers through the Open Acceleration Stack. HPC nodes can dispatch quantum subroutines, while classical accelerators close low-latency loops with the controller for tasks such as QEC decoding, calibration, optimization, and feed-forward. With OPNIC, external CPUs, GPUs, and FPGAs can operate next to the QPU in the microsecond regime, while Slurm, Kubernetes, and other HPC tools manage resources from the classical side. This gives HPC centers a practical path to develop, benchmark, and deploy quantum workflows before and after quantum hardware is available.
A layered classical-quantum architecture
QM delivers best-in-class platforms for integrating quantum processors into HPC environments, enabling seamless coupling of quantum systems in existing infrastructures. This empowers researchers to move beyond experimentation towards practical applications with real-world impact. HPC nodes dispatch quantum workloads to a heterogeneous control stack (classical accelerators connected via the Open Acceleration Stack), which closes the real-time loop with the OPX1000 in microseconds. QEC decoding, calibration, and feedback run next to the qubits, off the HPC’s critical path. From the HPC side, the workflow is familiar. Allocate the resource through your scheduler (Slurm, Kubernetes) and run. For example, a common use of quantum computing is parameter optimization (known as VQE, Variational Quantum Eigensolver), used to find a molecule’s ground-state energy. The optimizer runs on the HPC node, while quantum circuits execute on the OPX1000. The control stack handles low-latency operations, including QEC decoding and measurement processing, returning energy estimates that drive the next optimization step.
Measuring latencies: a working classical-quantum loop
Fault-tolerant quantum error correction (QEC) requires decoding in real time, faster than the syndrome extraction rate, to avoid growing backlog where the loop falls behind, and the computation fails. In recent work with NVIDIA, we measured the feed-forward latency (FFL) of a controller-decoder unit: the time from the last measurement in a decoding task to the conditional pulse it triggers. In a standard QEC loop with a GPU-resident decoder, the Grace Hopper to OPX1000 round-trip over OPNIC is 2.2 μs. The figure breaks down the remainder of the FFL budget. The full round-trip meets the microsecond-scale requirements of QEC.

A QPU-independent development platform
The QPU-independent development platform, built on QM’s Open Acceleration Stack, is our solution for HPC vendors who want to start integration work today. It pairs an OPX1000 and an accelerator via OPNIC, with reference programs that run on on the user side. Your classical computer connects over Ethernet: a dev server on day one, an HPC node in production. The Software framework can inject simulated QEC measurements (e.g. via Stim, a standard QEC simulator), so the classical-quantum loop runs end-to-end without a QPU. Use it to benchmark latency, develop the surrounding stack (scheduling, Slurm, hybrid jobs), and validate the integration before quantum hardware is on site. Once you have a QPU, you connect it and the stack you built runs unchanged. Other examples cover workloads like fault-tolerant quantum computing and ML-driven tasks including calibration and optimization.


FAQs
How do HPC users submit and schedule quantum jobs?
Through the same tools they already use — allocate the resource through your scheduler (Slurm, Kubernetes) and run. At the applications layer, HPC clusters schedule hybrid jobs in milliseconds, so QPU jobs enter the queue like any other computing accelerator. The classical accelerators then close the low-latency loop with the controller for the real-time work, keeping that complexity off the user-facing scheduling side.
What is QM’s Open Acceleration Stack, and what does it do for HPC centers?
The Open Acceleration Stack is QM’s modular framework for connecting hybrid controllers directly to classical accelerators — CPUs, GPUs, and FPGAs — so heavy classical computation runs inside the quantum runtime. It lets QEC decoding run on high-performance accelerators while the controller streams syndromes to the server and feed-forward closes the loop, and it’s built for the data center: HPC-QC integration from the quantum control layer up, scaling by adding OPX1000 controllers as the QPU grows and accelerator servers as compute demand grows.
What round-trip latency can the classical-quantum loop achieve, and why does it matter?
The OPNIC interconnect keeps the OPX1000-to-accelerator round-trip in the microsecond regime, with controller-accelerator round-trip latencies of 4 µs, while the control layer itself applies feedback in hundreds of nanoseconds. This matters because fault-tolerant QEC requires decoding faster than syndromes are extracted. Otherwise a backlog grows and the computation fails. So the loop has to stay within the roughly 1few µs budget (for superconducting qubits) for useful decoding. Keeping the full round-trip well under that bound is what makes real-time error correction possible.
Which classical accelerators and vendors does the platform support?
The stack is vendor-flexible by design, supporting CPUs, GPUs, and FPGAs across multiple vendors, including NVIDIA Grace Hopper and Grace Blackwell superchips, Intel and AMD x86 CPUs, and dedicated FPGA decoders such as Riverlane Deltaflow and the AMD FPGA Decoder. Centers aren’t locked into a single accelerator choice.
Can we develop and benchmark the integration before we have a QPU?
Yes. QM’s QPU-independent development platform pairs with an OPX1000 and an accelerator over OPNIC, with a software framework that can inject simulated QEC measurements (for example via Stim, a standard QEC simulator). This lets the full classical-quantum loop run end-to-end without quantum hardware on site, so teams can benchmark latency, build out the surrounding stack (scheduling, Slurm, hybrid jobs), and validate the integration in advance. When a QPU arrives, you connect it and the stack you built runs unchanged.
