The Architecture Blueprint for Hybrid Quantum-Classical Supercomputers
The race to fault-tolerant quantum computing is as much about classical integration as it is about qubits. As devices scale, workloads require more powerful classical resources for control, calibration, and quantum error correction.
Together with our partners at QOLAB, HPE, Fermilab, and others, Quantum Machines believes in a layered approach to quantum-classical integration towards quantum supercomputers (listen to Nobel Prize winner John Martinis to find out more!).
Our blueprint defines this approach as a hierarchy of classical resources, each operating at a distinct latency.
The first layer is about control: quantum system controller, such as Quantum Machines’ OPX1000, transforms mere qubits into a functional quantum processing unit (QPU) with real-time orchestration, mid-circuit measurement, and quantum feedback in hundreds of nanoseconds. The second layer is about accelerators: bounded-latency CPU-GPU servers handle online calibrations, optimizers, and QEC decoding, in microseconds. And the third layer is about applications: HPC clusters schedule hybrid applications in milliseconds, so QPU jobs enter the queue like any other computing accelerator.
Building on the collaboration between Quantum Machines and NVIDIA that led to the development of DGX Quantum, NVIDIA has recently introduced NVQLink, its open architecture for quantum-classical integration, setting a clear milestone for the second layer of this blueprint.
A layered architecture for classical integration
Our approach categorizes classical resources in three different networks, each with its own functionality, interfaces, and required latency.
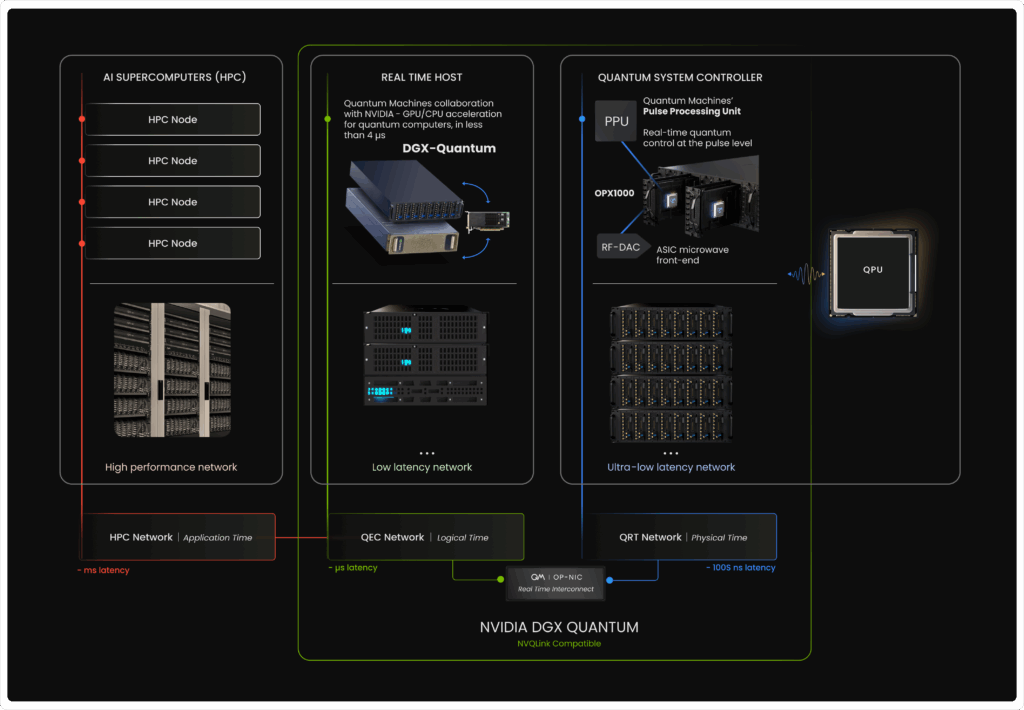
Figure 1 – Quantum Machines’ vision for the integration of quantum and classical resources pushing towards hybrid quantum supercomputing. Different classical resources are managing different time scales. The quantum system controller OPX1000, operates within tens to hundreds of nanoseconds range, and the NVIDIA DGX Quantum CPU-GPU server, demonstrates a roundtrip latency of less than 4 microseconds.
1) Ultra-low latency control (QRT network, ~hundreds of nanoseconds latency)
This tightest network connects the quantum controller to the QPU. Here the pulse processing unit (PPU) embedded in the OPX1000 shapes pulses, enforces deterministic timing, performs mid-circuit measurement, and applies feed-forward within the quantum runtime. The goal is to keep the control loop physically close to the device to allow feedback within hundreds of nanoseconds or less. Strict timing is essential in order to perform operations on qubits much faster than their coherence time. The regime where latency must be compared with qubit coherence is what we call Quantum Real Time (QRT This is how qubits operate together as a QPU, ready for integration with higher layers.
2) Low-latency acceleration for decoding and calibration (QEC network, ~microseconds latency)
The middle network links controllers to dedicated acceleration servers that typically host GPUs and CPUs but can also include FPGAs or ASICs. This is necessary because with larger quantum systems comes the ever-greater need for powerful classical computation, for decoding, compilation, calibration, etc. With Quantum Machines-NVIDIA collaboration on DGX Quantum, we established the foundational building blocks that underpin the NVQLink architecture. The quantum system controller streams readout and syndromes over a bounded-latency fabric, managed by the real-time interconnect, QM’s OP-NIC. CPU/GPU (e.g. CUDA) kernels compute decoders, optimizers, or RL policies, then push data back before the next shot. Many such feedback operations involving classical accelerators can thus be executed intra-shot. Roundtrip latencies below 4 microseconds and bandwidths above 64 Gb/s keep even demanding decoding tasks within the required timescale for real-time QEC and online calibration. If QRT classical compute brings us from qubits to physical QPU, the QEC layer elevates it to a logical QPU.
3) High-performance orchestration and applications (HPC network, ~milliseconds latency)
The outer network links to a standard HPC cluster that compiles circuits, runs large calibration campaigns, manages data, and schedules hybrid applications. From the developer’s perspective, CUDA-Q provides a unified hybrid programming model to co-program CPU, GPU, and QPU resources. This way, QPU jobs enter the same queue as any other accelerator workload and automatically inherit datacenter policies for scalability and reliability. Over time, quantum computers will take their place as accelerators within a broader, heterogeneous HPC ecosystem, one where every compute resource is applied to what it does best. Classical resources will continue to advance quantum computing, while quantum systems, in turn, will accelerate classical supercomputing.
Workflows traverse the full stack: HPC systems run hybrid applications, the QEC layer performs compute-intensive operations within the loop, and the QRT layer enforces precise timing and applies feed-forward on hardware, turning qubits into a truly functional QPU. The separation allows each band to scale independently, for example, adding GPU nodes for more advanced decoders, or expanding controller count for more qubits, without rewriting the entire software stack. NVQLink helps stitching together these networks, ensuring deterministic latency and throughput from controller to accelerator to HPC cluster. This is the practical path from lab rigs to quantum-classical supercomputers that run real workloads at scale.
Current state-of-the-art and NVQLink compliance
NVIDIA DGX Quantum laid the foundational building blocks for NVQLink and is, today, the reference implementation for tight CPU-GPU-QPU coupling. The system connects Quantum Machines’ OPX1000 controller to an NVIDIA real-time host and CUDA programmable accelerators via QM’s OP-NIC, acting as a real-time interconnect. OP-NIC is a QM product designed to connect the OPX1000 controller with any accelerator (CPUs, GPUs, FPGAs, ASICs). It creates a bounded-latency interface where classical compute runs inside the quantum runtime. Roundtrip latency is demonstrated to be under 4 microseconds, and the bandwidth exceeds 64 Gb/s, keeping decoders, optimizers, and online calibration tasks within the required latency for real-time operations.
NVQLink builds on these building blocks. It specifies a unified programming path with CUDA-Q, so hybrid applications can co-program CPU, GPU, and QPU without bespoke glue code, and it targets time-bound latency between the controller plane and the acceleration plane. QM’s implementation is NVQLink-compliant by design, integrating OPX1000 with NVIDIA servers through the OP-NIC while exposing standard tools like QUA, CUDA, and Python. This keeps the stack portable across datacenters and ready for HPC schedulers that will place QPU work in the same queue as other accelerator jobs.
For example, the controller can stream readout and syndrome data to the accelerator, where CUDA kernels evaluate decoders or reinforcement-learning policies, and trigger QUA feed-forward operations to apply corrections or update pulse parameters before the next shot. This workflow has been implemented for online calibration and QEC decoding, demonstrating end-to-end dataflow and programmability by using NVQLink framework and device calls.
Watch the video below to hear from our CTO, Dr. Yonatan Cohen, explain the DGX Quantum programmability via CUDA-Q.
What’s to come: a vision realized and a future enabled
This blueprint is already in use. Quantum Machines supports world-leading labs pairing OPX1000 control with GPU acceleration on NVIDIA DGX Quantum. Diraq was among the first adopters, highlighted in a recent QM–Diraq seminar with results on heralded qubit initialization and improved readout using reinforcement learning on GPU. At École Normale Supérieure de Lyon, DGX Quantum is used for real-time pulse calibrations with AI, and at MIT it accelerates stabilizer rounds for qLDPC error-correcting codes. More updates are forthcoming from Fraunhofer Institute, Academia Sinica, the Israeli Quantum Computing Center, and others.![]()
What comes next is breadth and scale: more qubits under real-time control, deeper decoders and optimizers running within microseconds, and hybrid applications that HPC schedulers treat like any other accelerator job. As hybrid systems proliferate, facilities can scale by adding controllers, HPC integration with different GPUs and QPUs will become easier and more standardized, all with modular steps without rewriting the stack.
The payoff of all this is practical: faster bring-up, steadier fidelities over long runs, and QEC that keeps pace with device growth. Researchers gain iterative science in real time, operators get predictable performance, and developers keep a single programming path from circuit to supercomputer. The groundwork is laid for quantum-accelerated supercomputing.

