Open Acceleration Stack
An open and modular acceleration framework breaking the boundaries between classical and quantum computing: classical acceleration for quantum error correction, calibrations, and more.
Meet Quantum Machines’ Open Acceleration Stack, a modular framework for hybridization of quantum and classical compute resources. It connects QM’s hybrid controller directly with classical accelerators (CPUs, GPUs, and more). The large selection of high-bandwidth integrations and time-bounded communications allows the Open Acceleration Stack to provide the necessary amount of classical compute resources and response latencies needed by your quantum systems. It closes the loop in microseconds, enabling quantum error correction, rapid calibrations, machine-learning routines, adaptive experiments, and paving the way to classically-accelerated quantum supercomputing.


QM’ low-latency interface PCIe card handling data marshaling between hybrid controllers and any classical accelerators in microseconds

Integrating dedicated FPGAs for decoding, such as Riverlane Deltaflow and AMD FPGA Decoder.

GPUs allow efficient machine learning algorithms for qubit calibrations and drift corrections. Ready with full NVQLink compliance


When both CPU and GPU resources are needed, superchips are the solution. Integrate today NVIDIA GraceHopper, Grace Blackwell, and more


Integration of X86 Intel CPUs and AMD CPUs with 2-3 µs latency for all classical processing needs within quantum workflows

QM’s flagship hybrid controller
Highest channel density, Cutting-edge analog front-end, Adaptive control at any scale


The Open Acceleration Stack is a modular framework designed to tightly couple classical compute resources to QPUs with bounded-latency integration, so classical acceleration becomes part of the quantum runtime. At its core is the OPX1000 Hybrid Controller, powered by the Pulse Processing Unit. QM’s OPNIC couples the controller to any server, with CPUs, GPUs, FPGAs, and more, from a variety of vendors and any compute power. Boost your quantum system with classical acceleration for real-time calibration of qubit parameters and quantum error correction decoding at scale.
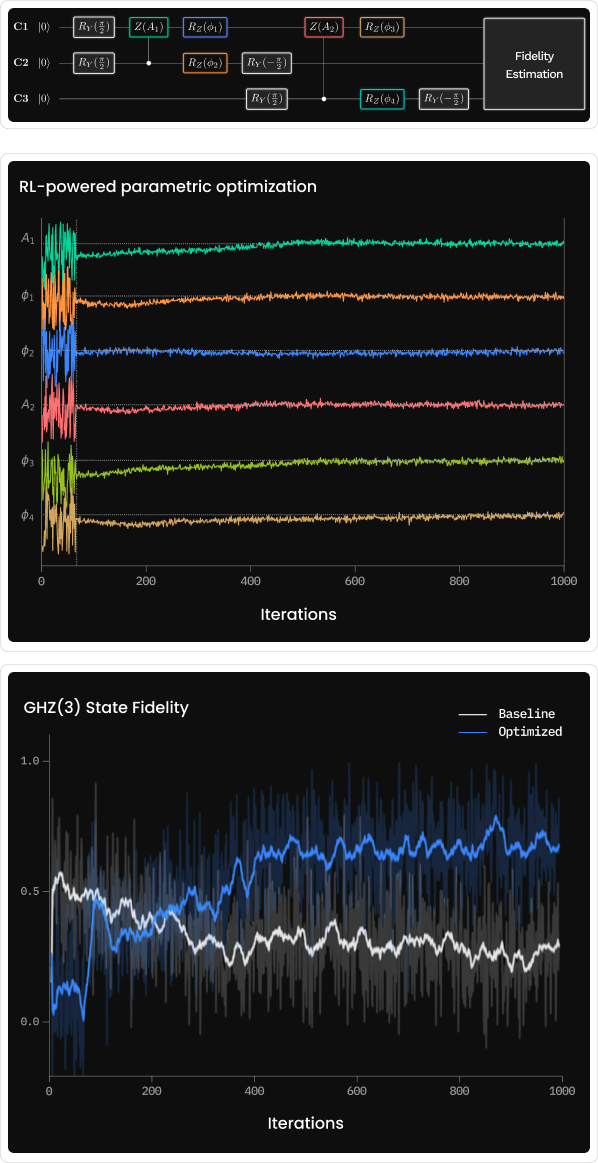
Integrating quantum systems with classical resources is especially valuable for online calibrations, where powerful classical accelerators make it possible to use more computationally demanding methods. With implementations of QM’s Open Acceleration Stack, calibration routines run as a closed loop inside the experiment: the system coordinates shots, streams readout to the classical accelerator, evaluates optimizers or reinforcement-learning (RL) policies, then updates control parameters before the next shot. Connecting an OPX1000 hybrid controller with an NVIDIA GraceHopper, and considering a 3-qubits GHZ routine, we show the online RL optimizes 6 pulse parameters consistently exceeding the best pre-calibrated baseline, and correcting drifts that static routines miss.
The payoff is practical: fewer manual retunes, faster bring-up, higher and steadier fidelities across long runs, and a template that scales to large QPUs and more complex sequences. This demonstrates how tight GPU-CPU-QPU integration transforms calibration from a one-off, time-consuming step into continuous real-time optimization: clear evidence of the dawn of quantum-accelerated supercomputing.
Quantum error correction only works if the decoding speed keeps up with the error rate, and as QPUs scale up, the required classical computation becomes increasingly resource-intensive. QM’s Open Acceleration Stack allows QEC decoding to run on high-performance classical accelerators, so the heavy lifting happens on a powerful CPU-GPU server. The quantum system controller runs stabilizer rounds on the QPU, and streams error syndromes (measurement results) to the server. A separate kernel (e.g. CUDA kernel) decodes syndromes and computes corrections, sending the information back to the controller, where feed-forward operations close the loop. Between an OPX1000 and an NVIDIA GraceHopper, the communication roundtrip latency is kept below 4 µs, allowing the decoding time budget to remain below the 10-20 µs limit for useful decoding [Kurman, et al. arXiv:2412.00289 (2024)]. The result of using the Open Acceleration Stack to integrate acceleration servers into quantum sequences is real-time QEC that scales: larger codes, deeper rounds, and higher-throughput experiments without rewriting the stack.
Protocols can be written in CUDA-Q: a single, unified hybrid programming language that defines a quantum circuit, data streaming, device calls, and the quantum feedback to apply corrections. This keeps real-time quantum orchestration, decoding, and control in one place, aligned and fully compatible with NVIDIA NVQLink’s open model for bounded-latency quantum-classical integration. As codes grow and decoders evolve, classically accelerated QEC decoding offers the scale and flexibility needed for fault-tolerant quantum computing.
The first system to integrate classical accelerators in quantum sequences, and demonstrate QEC workflows and AI-based calibrations on GPU.
Microsecond-level controller-accelerator roundtrip latencies (2-4 μs).
Natively supports programming in CUDA, CUDA-Q, C++, Python, and custom device calls.
Designed for any scale, from cost-efficient servers to cutting-edge data centers.
Run the Most Advanced Hybrid Algorithms
The only solution with demonstrated support for quantum error correction and reinforcement-learning-based calibrations
Effortless Scalability
Add OPX1000 controllers as your QPU grows, and add accelerator servers to meet increasing computational demands
HPC & Data Center Ready
HPC-QC integration from the hardware quantum control layer and up, designed for data center reliability with redundancies and hot swappable critical parts
Compatible with All Qubit Technologies
The Open Acceleration Stack supports superconducting qubits, spin qubits, neutral atoms, trapped ions, defect centers, photonic qubits and more
Wide Language Support
The Open Acceleration Stack natively supports programming in CUDA, CUDA-Q, C++, Python, and custom device calls, for co-development of hybrid workflows.

Have a specific experiment in mind and wondering about the best quantum control and electronics setup?

Want to see what our quantum control and cryogenic electronics solutions can do for your qubits?