Classically Accelerated Readout for Neutral Atoms with CPU/GPU Integration
Neutral-atom quantum computers are quickly becoming the most promising path to fault-tolerant quantum computing. They are the only qubit modality that have scaled to thousands of physical qubits. Quantum Error Correction (QEC) cycles have been demonstrated on real hardware, including repeated error detection and correction across multiple rounds.
However, readout, a key step for any QEC cycle, takes orders of magnitude longer than gate operations, making it a central bottleneck.
At Quantum Machines, we have developed a dedicated server-based readout solution for neutral-atom systems that reduces latency across the control stack. Built around a CPU/GPU server connected to the OPX1000 through OPNIC, the solution also supports QEC decoding and circuit parameter optimization. OPNIC delivers the readout results, transport instructions, and correction commands to the OPX1000 in time for the next sequence of operations. By closing this loop with deterministic low latency, the system removes readout as the main bottleneck.
Because every QEC cycle depends on measurement outcomes, this solution directly improves mid-circuit corrections, atom transport, and overall code performance.
Overall, this opens the possibility to run compute-intensive programs on the server side with minimal latency overhead, without compromising deterministic timing of the OPX1000.
Why is readout slow?
State discrimination is key for reliable quantum computing. In neutral atoms, the qubit states are encoded in the hyperfine ground states of the atom, and the readout is camera based. A global resonant laser drives fluorescence, and a high numerical aperture camera, typically an sCMOS or EMCCD, collects the scattered photons. Atoms in the bright state scatter light while the atoms in the dark state produce no signal.
However, atoms emit only a small number of photons. A good signal-to-noise ratio (SNR) typically requires increasing the laser intensity or extending the exposure time. Both are not ideal as high intensity can knock atoms out of the trap while longer exposure directly adds to the latency, slowing every subsequent step of the computation. This makes readout inherently challenging. A desirable readout process would use low intensity and short exposure times. But each makes the other harder to achieve.
But photon collection is only half of the story.
Reducing readout latency means improving signal-to-noise ratio to the point where state discrimination is reliable even with limited photon collection. Achieving this at short exposure and low intensity demands improvements in both camera technology and image processing. Once the camera shutter closes, the challenge shifts to the control stack. As arrays scale to running algorithms, readout data transfer and the compute required on it become increasingly demanding. In simple setups, the camera data is processed on a host, and the resulting occupation matrix is sent back to the OPX1000 over Ethernet. This can work for simple readout, but the Ethernet transfer becomes a limiting step both in bandwidth and in latency predictability.
Modern scientific camera interfaces address this by sending image data over coaxial links to a PCIe frame grabber, which transfers the data directly into server memory with consistent, predictable timing. This provides a much more predictable camera-to-server path for low-latency processing. Once the image data reaches the server with low transfer latency, the readout pipeline can move beyond simple thresholding to more compute-intensive processing on CPU or GPU server. The server can then use that readout output to run algorithms such as atom transport, mid-circuit syndrome extraction, and even QEC decoding.
But computing fast on the server is only useful if the results reach the controller in time. Passing corrections to the controller over the ethernet introduces variable delays that are incompatible with the timing demands of a QEC cycle.
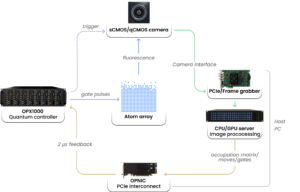
End-to-end schematic of the readout solution. The OPX1000 triggers the camera which then transfers the data over a camera interface to the server via a frame grabber. Custom software performs image processing on the server. The occupation matrix, transport moves, gate corrections can be sent to the OPX1000 at 2 microsecond latency via the OPNIC. The OPX1000 can then perform the next round of pulses.
Fast, intelligent readout
This is where OPNIC completes the loop of our readout solution. Quantum Machines’ OP- Network Interface Card (OPNIC) creates a deterministic, microsecond-level link between the server and the OPX1000. This means that transport moves and correction operations computed on the server can reach the OPX1000 to close the feedback loop within a single QEC cycle.
The end-to-end operation of this stack looks like this. The OPX1000 triggers the camera to take an image which arrives at the frame grabber and is transferred to the host memory. QM’s software stack extracts the occupation matrix using image processing algorithms. A route planner determines which atoms need correction or replacement and computes collision-free, minimal jerk transport paths. The OPNIC, a PCIe card that can be slotted into the server, relays the results to the OPX1000. This could mean triggering rearrangement, reloading, applying selective correction pulses, or updating gate parameters, all within the quantum runtime. For transport, the move instructions can be directly streamed to the OPX1000 via OPNIC in 2 µs, requiring no waveform upload.
Critically, all this can operate in a non-blocking mode. In other words, fwhile the camera exposure and pixel transfer are in progress, the OPX1000 continues executing other operations, polling the server at microsecond intervals. When the result arrives, it is consumed immediately. This maximizes utilization of the time available during the readout window and keeps the quantum program moving.
The readout solution works with any off-the-shelf camera, frame grabber, and server. Depending on computing requirements, different server configurations can be chosen, from cost-efficient CPU-based to GPU-accelerated systems. Along with OPNIC, our solution provides software support that simplifies building and deploying hybrid quantum-classical programs in Python on this stack, with the flexibility to write your own image processing algorithms. This eliminates the need for expertise in low-level GPU programming or manual orchestration of server-side and QUA programs.

Readout timeline for a 10×10 array using 1 core of the Lenovo workstation. The OPX1000 triggers the camera which writes the image onto the CPU/GPU server in 442 µs. The server performs image processing (21 µs) before the OPNIC streams results back to the OPX1000 (2 µs) which then sends out the next round of corrections, closing the loop in under 500 µs. Time axis is square root-scaled for clarity. Note that in this benchmark the captured image is not used for classification; the processing stage runs a pre-loaded 10×10 reference image. The capture stage is therefore included to represent the realistic per-shot data transfer cost, not as input to the downstream classification.
On a Lenovo P7 workstation connected to an OPX1000 over OPNIC, we benchmarked matched-filter and CNN-based state classification and action planning algorithms. Matched filters offer a computationally lightweight approach to state discrimination by correlating the fluorescence image against a known point-spread function, improving SNR without requiring longer exposure times. CNN-based classifiers extend this further, enabling reliable discrimination even at very low photon counts. Using a Teledyne Kinetix camera, readout of a 10×10 array (100 sites, 8×8 pixel patches), the readout cycle completes in 460 µs per cycle at a 200×1500 ROI using 1 core, including 21 µs for classification, with 99.9% per-site occupancy fidelity on our reference calibration set. For 2400 sites and using 24 cores of the server, the image processing takes 85 µs.
Beyond readout to decoding
Beyond readout and transport, the same server pipeline enables QEC decoding. Decoding starts with syndrome extraction which involves measuring a subset of qubits and identifying errors, while preserving the coherence of the rest of the system. Standard readout can induce heating and atom loss, so maintaining performance requires low-latency readout and correction before errors accumulate. Co-locating the decoder on the same server as the readout processing, and connecting to the OPX1000 via OPNIC, means corrections are recognized, computed and applied within the same setup without adding to the latency.
Once syndrome measurements are extracted, a server computes the required corrections in real time before the next gate sequence, including identifying atom loss and issuing commands for qubit reloading or local control operations.
In this way, QM’s readout solution tightens each segment of the full readout-to-correction loop. But there is still room to improve these latencies further. On the camera and frame grabber side, exposure timing, pixel readout speed, and how data is transferred into host memory can all be optimized independently of the control stack. These are active areas of development in both camera hardware, high-speed data acquisition, as well as how control stacks interface with them.
That said, the results presented here already make meaningful progress toward the readout latencies required for QEC. Neutral atom QEC cycles require total readout-to-correction latencies on the order of a few hundred microseconds, and the pipeline described here already brings the latency in the ballpark. Realizing this requires tight integration between the QPU, OPX1000 and classical accelerators via the OPNIC. The hybrid architecture is what moves neutral-atom platforms beyond demonstrating atom trapping and coherent control toward utility-scale computation, where mid-circuit readout drives real-time atom rearrangement, error correction, decoding, and adaptive feedback within the coherence-limited execution window.
Whether your lab is controlling hundreds of atoms today or building fault-tolerant systems at scale, the infrastructure needs to be in place so that the physics can be fully explored.
If you are working on neutral atom systems and want to see this in action, request a demo.

